
Image annotation is the task of enhancing data with additional information. The added information can be used to generate additional value out of it. Let’s take a simple image as an input.
If we take a look from an information perspective, the computer gets an image file that describes every pixel on the screen. If we assume it is saved as an RGB file, every pixel contains 3 data points. One field of the human would look like that: [0, 0, 0] | [R, G, B]. Hence the computer only knows the color information and the positional arguments. Altogether we have 10 x 10 x 3 = 300 data points.
To enhance the information richness of the image we can make annotations. Such as drawing a bounding box around a specific object and describe it with a class. Herby, we draw a bounding box around the human.
Now the image is annotated and we enriched the information with the class “human” and the position of the human. Usually, we define the position of the upper left corner of the object with their distances to the left and to the top and their width and height. In the upper case, it would result in an additional JSON file of the annotation.
{“human”: { left: 5, top: 2, width: 3, height: 7}}
If we now think again about the information density we can enrich all enclosed pixels with the class “human”. An information vector of a pixel of the human would look like [“human”, 0, 0, 0] | [class, R, G, B]. Therefore we now have 24*4 + ((100–24) * 3) = 324 data points to calculate with. As you can see just with one label we can enhance the information density of the image.
How can we make such annotations?
Annotations are usually done by a so-called annotation software and are made by humans. There are several providers out there, to name some:
- Manthano.ai
- Dataurks
- Playment
- Colabeler
- Supervise.ly
- LabelBox
- Amazon Sage Maker
- ReactLabel
- Basic AI
- Dataloop
- LOST
- V7LAbs
- SuperAnnotate
- Labelstud.io
- Hasty.ai
- Segments.ai
Those annotations can be done on the desktop or on mobile devices. We Manthano provide a mobile solution (bottom) and Labelbox as an example provides a desktop solution (top).
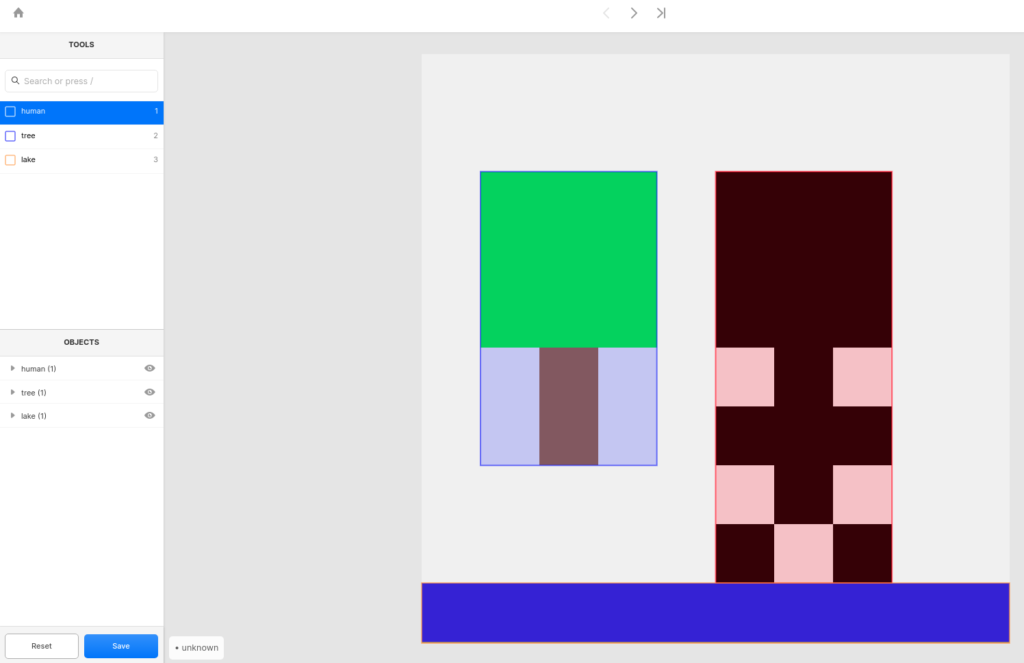
Most of those annotation software companies also provide annotation services, which means that the annotation is not done by yourself but from other people mostly in cheaper countries. They will get instructions from the client. Usually, the higher the volume of the needed images and annotations and the lower the know-how the easier it is to outsource the job.
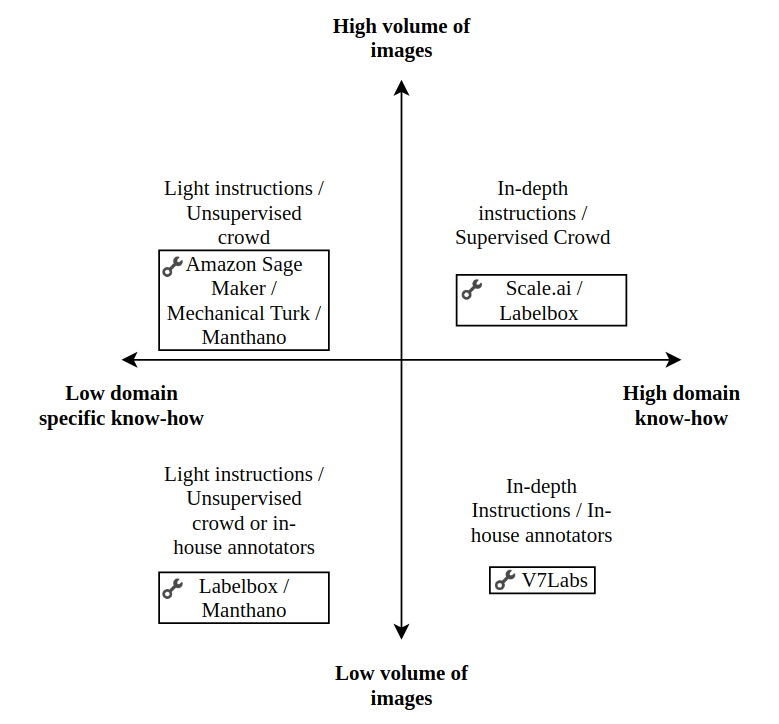
As you can see in the upper representation every company is focused on a different area and is more suitable to the given situation. If you find yourself creating an image dataset think about the volume and the needed know-how. E.g. We wouldn’t suggest outsourcing a heart disease detection dataset (low-volume of images / high domain knowledge), but we would suggest outsourcing an autonomous driving dataset (high-volume / low domain knowledge).
If you have an upcoming project and you are unsure about which tool you should use, you can contact us, we are open to help. Happy about your feedback.